📗〔讀書心得〕- SRE Ch2:Google 生產環境與 Borg 架構解析
- 📗〔讀書心得〕- SRE Ch2:Google 生產環境與 Borg 架構解析
- 硬體故障是常態:軟體定義的硬體管理
- Google 的開發環境:單一程式碼庫
- 一個使用者請求的旅程:從點擊到服務
- 我的 TAKEAWAY
- Extended Reference & FYI
這篇文章將聚焦於《Site Reliability Engineering》中的:
講解 Google 的生產環境如何運作,包含資料中心硬體設計、叢集作業系統 Borg、儲存與網路架構、以及 SRE 在其中的角色與挑戰。
你可能會好奇,在 Google 這樣一個服務遍布全球的巨型組織中,SRE 團隊究竟是在什麼樣的基礎設施上工作?這是一個很好的問題。Google 的資料中心與你想像的傳統資料中心截然不同。這些差異不僅帶來了獨特的挑戰,也催生了許多創新的解決方案。
首先,我們來釐清兩個重要的名詞:
- 機器(Machine):指的是硬體實體,或虛擬機器(VM)。
- 伺服器(Server):指的是提供服務的軟體程式。
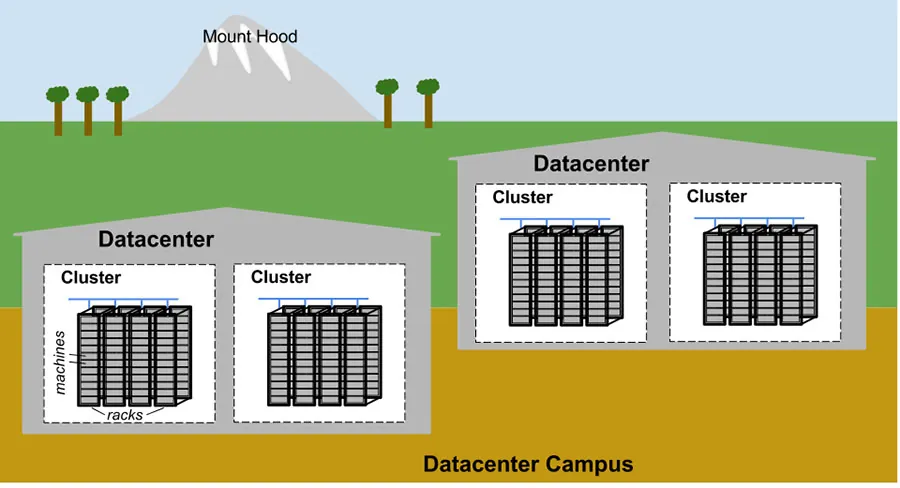
在 Google 的資料中心裡,沒有所謂「專門跑郵件伺服器」的固定機器。資源的分配是由一個名為 Borg 的叢集作業系統全權管理 ( kubernetes 的前身 )。這意味著,任何一台機器都可以隨時運行任何一個伺服器程式。當你將硬體與軟體解耦,會發現這正是實現大規模延展性(Scalability)與可靠性(Reliability)的關鍵。
硬體故障是常態:軟體定義的硬體管理
在 Google 的龐大叢集裡,硬體故障是家常便飯。以單一叢集為例,每年都有數千台機器和硬碟故障。當這個數字乘以全球所有資料中心時,你會發現這是一個驚人的管理規模。
為了讓使用者和維運團隊不需為此煩惱,Google 透過軟體來管理硬體故障,讓故障問題能夠被抽象化。這背後的關鍵系統是:
- Borg:叢集作業系統Borg 是一個分散式叢集作業系統,功能類似於 Apache Mesos。它負責在整個叢集層級管理工作(Job)。當你需要運行一個伺服器時,你只需告訴 Borg 你需要多少資源(例如 3 個 CPU 核心、2 GiB 記憶體),Borg 就會自動為你找到一台合適的機器來運行你的程式。如果你的程式意外終止,Borg 也會自動將其重新啟動,甚至可能換一台機器。
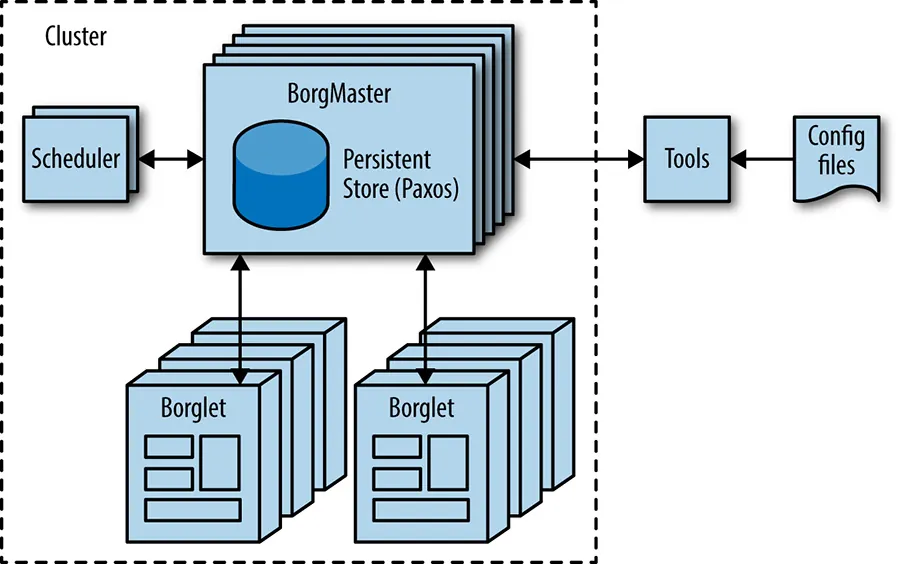
Borg Naming Service(BNS):
既然伺服器程式會動態地在不同機器上運行,我們就不能再依賴固定的 IP 位址來存取它們。為了解決這個問題,Borg 啟動每個任務時,都會給予一個唯一的名稱和索引,這就是 Borg Naming Service(BNS)。其他程式可以透過 BNS 名稱來存取服務,而不需要知道背後實際的 IP 位址和連接埠。這個抽象層,讓服務的位置變得彈性且透明。
For example, the BNS path might be a string such as /bns/<cluster>/<user>/<job name>/<task number>, which would resolve to <IP address>:<port>.
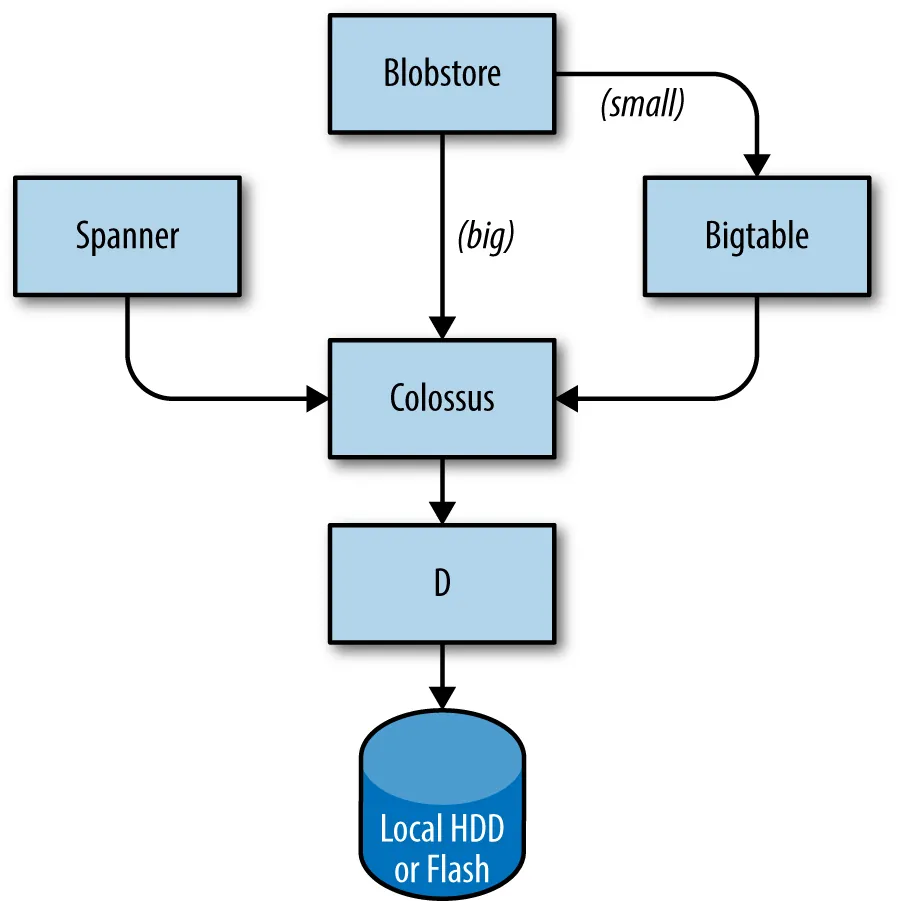
Google 的儲存系統:多層次架構
Google 的儲存架構層次分明,確保了資料的可靠性與存取效率,同時為不同應用場景提供最合適的解決方案。
- D(Disk):底層檔案伺服器
- D 是最底層的檔案伺服器,直接在幾乎每台機器上運行,負責管理和存取單一機器上的本地硬碟或 SSD。(傳統單機的檔案系統,是所有上層儲存服務的基石)
- Colossus:叢集級檔案系統
- Colossus 建立在 D 之上,將所有機器上的D儲存空間整合為一個巨大的、叢集級的檔案系統。它是 Google File System (GFS) 的繼任者。
- 功能: 提供了跨機器的資料複製(Replication)與加密功能,確保即使單一機器或硬碟故障,資料也不會遺失。可以將它類比為業界熟知的 HDFS(Hadoop Distributed File System)或 Lustre。幾乎所有 Google 內部需要大規模儲存檔案的服務都使用 Colossus。例如,Gmail 會將你的信件檔案儲存在這裡;Google Drive 會將你的個人檔案儲存在 Colossus 上。
- Bigtable:大規模 NoSQL 資料庫
- Bigtable 是一個建構在 Colossus 之上的 NoSQL 資料庫系統。它擅長處理超大規模的非結構化資料,能輕鬆應對 PB 級別的資料量。
- Bigtable 提供了一個分散式、可持久化、多維度排序的地圖(map)結構,用來儲存大量非結構化或半結構化的資料。它支援最終一致性(Eventually Consistent)的跨資料中心複製。例如,Google Search 的網頁索引、Google Earth 的地形資料、以及 Google Finance 的時間序列資料,都儲存在 Bigtable 中。它適合需要快速讀寫大量非結構化資料的服務。
- Spanner:全球級強一致性資料庫
- Spanner 是 Google 用於需要全球級強一致性的分散式資料庫。它提供了類似 SQL 的介面,讓開發者能夠像使用傳統關聯式資料庫一樣,處理分散式系統中的資料。
- Spanner 最大的特色是它能實現全球同步與強一致性。即使你的資料分散在世界各地的資料中心,它也能保證讀取到的資料永遠是最新的,並支持跨地區(cross-region)的事務處理(transaction)。例如,Gmail 用戶的個人設定、Google Photos 的元資料(metadata),以及 Google Ads 的廣告設定等,都需要高度的資料一致性,這些服務都運行在 Spanner 之上。
- Blobstore:大型物件儲存
- Blobstore 是一個專門用來儲存大型、不可變動二進制物件(Binary Large Objects,Blob)的系統。
- 它可以讓你高效地儲存像影片、圖片、音訊檔案等大容量資料。這些物件通常不需要頻繁修改,但需要快速、穩定的存取。例如,YouTube 的影片檔案、Google Photos 的相片、以及 Google Play 上的應用程式安裝套件,都存放在 Blobstore 中。
Google 的軟體基礎設施
除了強大的硬體與分散式系統外,Google 的軟體基礎設施更是確保服務高效運作的核心。在 Google,程式碼架構的設計旨在最大化硬體資源的使用效率。
- 多執行緒架構: 程式碼被設計為高度多執行緒(Multithreaded),這讓單一任務能輕易地使用多個核心,充分利用現代處理器的運算能力。
- 內建診斷工具: 每個伺服器都內建一個 HTTP 伺服器,提供診斷數據與即時統計資訊,這使得監控、除錯和建立儀表板變得非常方便。
內部通訊:從 Stubby 到 gRPC
Google 內部所有服務之間的通訊都依賴一個名為 Stubby 的 遠端程序呼叫(Remote Procedure Call, RPC) 框架。Stubby 它是 gRPC 的前身,後來 Google 才基於 Stubby 的經驗它開放標準化為 gRPC。
為何使用 RPC? RPC 讓前端(Frontend)與後端(Backend)之間的通訊變得如同呼叫本地函式一樣簡單。即使是本地函式呼叫,也經常被設計成 RPC 的形式。這讓元件之間的解耦變得更容易,當服務的程式碼庫變得龐大時,可以更輕鬆地將其重構成獨立的
伺服器。資料傳輸:協定緩衝區(Protocol Buffers) 在 RPC 框架中,資料的傳輸採用名為協定緩衝區(Protocol Buffers,簡稱 protobufs)的序列化格式。與傳統的 XML 格式相比,protobufs 的優勢,包括更簡單、更直觀,而且檔案大小只有 XML 的 3 到 10 分之一,處理速度更是快上 20 到 100 倍。
.proto檔案的 example :``` syntax = "proto3"; package tutorial; // 定義一個 Person 訊息 message Person { string name = 1; // 姓名 int32 id = 2; // 唯一 ID string email = 3; // 電子郵件 } ```
Google 的開發環境:單一程式碼庫
在 Google,開發效率與程式碼品質至關重要。為此,Google 打造了一套內部的開發環境,其核心正是單一共享的程式碼庫(Monorepo)。
雖然部分開源專案(如 Android 和 Chrome)有自己的程式碼庫,但絕大多數 Google 的軟體工程師都在同一個程式碼庫中工作。這種模式帶來了幾個重要的優勢:
- 快速修復外部問題:如果工程師在自己的專案之外發現了一個問題,他可以直接在同一個程式碼庫中修復它,並將修改提案(
changelist,簡稱 CL)提交給該元件的負責人審閱。這大大簡化了跨團隊協作和問題修復的流程。 - 嚴格的程式碼審核:所有提交的程式碼都需要經過審核。這個機制確保了每一次的變更都符合高標準,從源頭上保證了軟體品質。
- 自動化建構與測試:當 CL 被提交後,建構請求會被傳送到資料中心的建構伺服器。由於建構過程是平行化的,即使是大型專案也能迅速完成。這套基礎設施同時也用於持續測試:
- 影響範圍測試:每次提交後,系統會自動運行所有直接或間接依賴於該變更的測試。
- 自動化通知:如果測試框架偵測到變更可能會破壞系統的其他部分,會立即通知提交者。
- 「綠燈即發布」系統:部分專案採用「push-on-green」系統,一旦所有測試通過,新版本就會自動部署到正式環境。
一個使用者請求的旅程:從點擊到服務
為了更具體地理解這些系統如何協同運作,讓我們使用一個簡單案例來進一步理解:一個名為「莎士比亞搜尋服務」的網站,它可以讓你查詢某個單字出現在莎士比亞所有作品中的位置。
以下是一個使用者請求的完整生命週期:
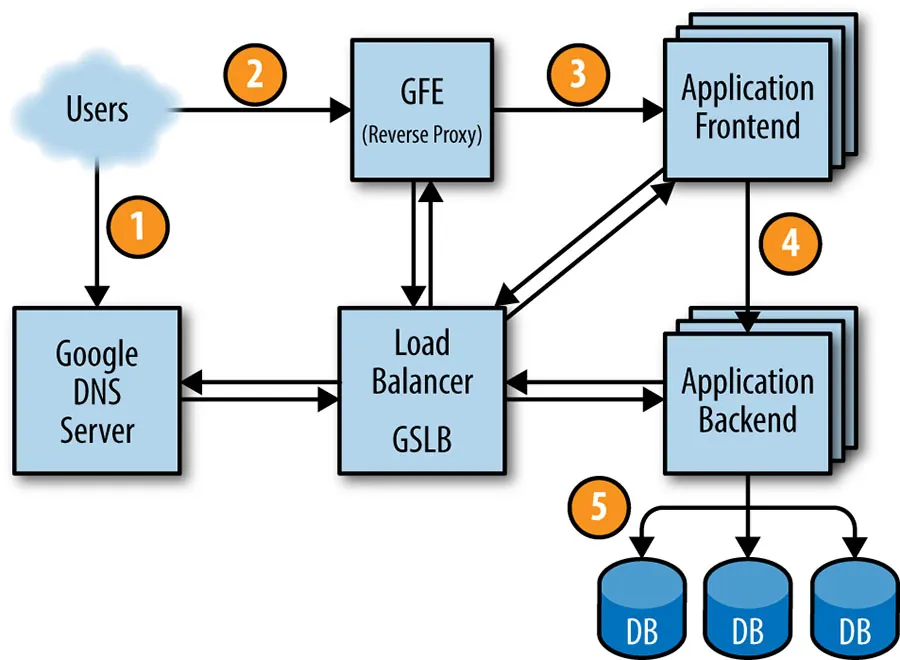
- 使用者點擊網址:使用者在瀏覽器中輸入
shakespeare.google.com,瀏覽器會向 DNS 伺服器發出解析請求。 - 全球負載平衡(GSLB):Google 的 DNS 伺服器與全球軟體負載平衡器(Global Software Load Balancer, GSLB)協同運作。GSLB 會根據使用者所在地理位置和各地區的伺服器負載情況,選擇一個最適合的 Google Frontend(GFE) 伺服器 IP 位址回傳給使用者。
- 前端伺服器接收請求:使用者的瀏覽器連線到 GFE 伺服器,GFE 伺服器作為反向代理,終止 TCP 連線後,會根據請求的服務類型(例如:搜尋、地圖或我們的莎士比亞服務),再次透過 GSLB 尋找一個可用的「莎士比亞前端伺服器」。
- 後端查詢:莎士比亞前端伺服器接收到請求後,會將使用者查詢的單字包裝成一個 RPC(Remote Procedure Call)請求。同樣地,它會再次聯繫 GSLB,尋找一個可用的「莎士比亞後端伺服器」。後端伺服器收到請求後,會向 Bigtable 儲存系統查詢資料。
- 回傳結果:Bigtable 回傳查詢結果給後端伺服器,後端伺服器再傳回給前端伺服器。前端伺服器將資料組合成 HTML 頁面,最終回傳給使用者瀏覽器。
這整個過程在數百毫秒內完成,看似簡單,背後卻是環環相扣的複雜系統。
在高可用性與容量規劃的實務考量
SRE 的一個核心職責,就是確保上述流程在任何情況下都能穩定運作。以案例「莎士比亞搜尋服務」為例,當我們進行容量規劃時,不能只考慮預期中的尖峰負載。
- N+2 冗餘原則
假設透過壓力測試,我們得知每個後端伺服器每秒能處理 100 次查詢(QPS),而預估的尖峰負載為 3,470 QPS。理論上,我們需要 35 個伺服器(3470 / 100 = 34.7)。但 SRE 會額外考量:
- 軟體更新時的風險:當我們進行軟體更新時,會一次只停用一個伺服器。這時,我們需要確保剩下的伺服器(34 個)依然能撐住流量。
- 硬體故障的風險:如果在更新期間,又有一台機器故障,我們還能保有 33 個伺服器,足以應對尖峰負載嗎?
因此,在 google 通常會採取 N+2 冗餘(N = 理論所需伺服器數量,+2 為額外備用)的策略,確保即使在更新或故障時,服務仍能穩定運作。
地理分散與成本權衡 如果服務的使用者分佈在全球各地,我們還需要考量地理位置。與其將所有後端伺服器都部署在同一個地方,SRE 會將伺服器分散到北美、歐洲和亞洲等地。這樣做的好處是:
- 降低延遲:使用者能被導向最近的資料中心,大幅縮短請求的處理時間。
- 提高韌性:單一地區的資料中心故障時,流量可以被重新導向到其他地區,保證服務的可用性。
不過,這個策略也需要和成本權衡。例如,如果使用者流量分佈為北美 1,430 QPS、歐洲 1,400 QPS、亞洲 350 QPS、南美 290 QPS,那麼:
- 北美需要 15 個伺服器(1,430 / 100 = 14.3)
- 歐洲需要 14 個伺服器(1,400 / 100 = 14)
- 亞洲需要 4 個伺服器(350 / 100 = 3.5)
- 南美需要 3 個伺服器(290 / 100 = 2.9)
根據 N+2 冗餘原則,我們會部署:
- 北美: 17 個伺服器 (15+2)
- 歐洲: 16 個伺服器 (14+2)
- 亞洲: 6 個伺服器 (4+2)
- 南美: 5 個伺服器 (3+2)
然而,SRE 可能會在在南美地區做出了 成本權衡。將冗餘從 N+2 降為 N+1,只部署 4 個伺服器。這雖然增加了些許風險,但在南美資料中心滿載時,GSLB 可以將流量重新導向至其他大陸的資料中心,藉由犧牲一點點 延遲來換取硬體成本的節省。
我的 TAKEAWAY
- 硬體故障問題難免會發生,透過 Kubernetes 和雲端服務,可以透過軟體的思維去進行維運,保持高可用性和高可靠性
- 全球性的大型服務,儲存系統進行分層,已應對不同場景
- 全球性的大型公司大型服務,會越來越走向 Monorepo ,當服務越來越多,各元件的版本管理會成為很重的負擔,Monorepo 可以減少版本管理問題,開發的複雜度降低很多 ; 但是也會有相應的 Tradeoff ,像是 規模與效能挑戰 、CI/CD 成本高昂、依賴管理與界線模糊,而 google 是透過打造內部的專屬系統 (
Piper、CitC、Blaze)和嚴格的 程式碼審核和「 程式碼所有者」(Code Owner)的機制,來解決 Monorepo 帶來的挑戰。- 參考延伸閱讀的 [2][3][4][5][6]
- 在成本的考量下,冗餘的規劃與地理分散(全球性的服務),可以進行適當的 tradeoff ,維持高可用性與成本的平衡。
Extended Reference & FYI
- https://medium.com/@mystery.girl.94/what-is-a-monorepo-and-trade-f7dbfae67e2c
- https://www.ptt.cc/bbs/Soft_Job/M.1747295625.A.D41.html
- https://www.pttweb.cc/bbs/Soft_Job/M.1747904496.A.E67
- https://en.wikipedia.org/wiki/Piper_(source_control_system)
- https://opensource.google/projects/bazel?hl=en
- https://gitmega.dev/
This Content is Authored by the writer, with AI-assisted proofreading and SEO optimization.
